A Step-By-Step Guide on Blocking AI Crawler Bots Using a Robots.txt File
Robots.txt File, are you a content creator or a blog author who generates unique, high-quality content for a living? Have you noticed that generative AI platforms like OpenAI or CCBot use your content to train their algorithms without your consent? Don’t worry! You can block these AI crawlers from accessing your website or blog by using the robots.txt file.
How to block AI Crawler Bots using robots.txt file
What is a robots.txt file?
A robots.txt is nothing but a text file instructs robots, such as search engine robots, how to crawl and index pages on their website. You can block/allow good or bad bots that follow your robots.txt file. The syntax is as follows to block a single bot using a user-agent:
user-agent: {BOT-NAME-HERE}
disallow: /
Here is how to permit specific bots to scan your website using a user-agent:
User-agent: {BOT-NAME-HERE}
Allow: /
Where should you put your robots.txt file?
You should upload the file to the root folder of your website. Hence, the URL will appear as follows:
https://example.com/robots.txt
https://blog.example.com/robots.txt
Refer to the below mentioned resources to understand more about robots.txt:
- An introductory guide to robots.txt offered by Google.
- Understanding robots.txt and its working explained by Cloudflare.
Methods to prevent AI crawlers bots
The syntax remains identical:
user-agent: {AI-Ccrawlers-Bot-Name-Here}
disallow: /
How to Block OpenAI
Please insert the following quadruplet into your robots.txt:
“`
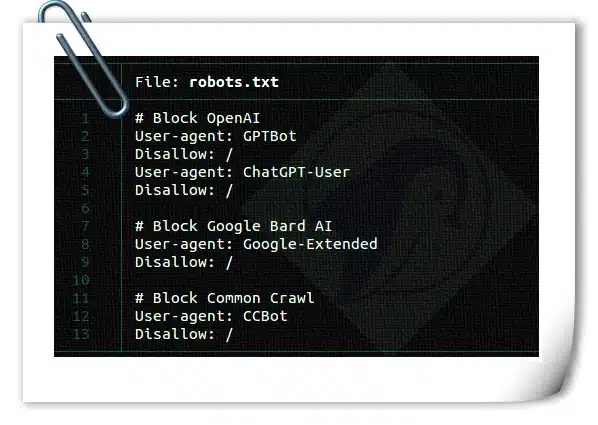
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
Robots.txt File, OpenAI utilizes two distinct user agents for web crawling and browsing, each having their own specific CIDR and IP ranges. Configuring the subsequent firewall rules requires an advanced knowledge of networking and root-level access to Linux. Should you be unfamiliar with these requirements, we recommend hiring a Linux sysadmin to help manage the changing IP address ranges, which can prove to be an ongoing issue.
#1: The ChatGPT-User is used by plugins in ChatGPT
Here’s a list of the varying user agents utilized by OpenAI crawlers and fetchers, along with the related CIDR or IP address ranges needed to block its plugin AI bot from your web server firewall. You can block the 23.98.142.176/28 range with either the ufw command or the iptables command on your server. For instance, check out this firewall rule to block a CIDR or IP range using UFW:
sudo ufw deny proto tcp from 23.98.142.176/28 to any port 80
sudo ufw deny proto tcp from 23.98.142.176/28 to any port 443
“`
#: The GPTBot is used by ChatGPT
Here’s a list of the user agents used by OpenAI crawlers and fetchers including CIDR or IP address ranges to block its AI bot that you can use with your web server firewall. Again, you can block those ranges using the ufw command or iptables command. Here is a shell script to block those CIDR ranges:
#!/bin/bash
# Purpose: Block OpenAI ChatGPT bot CIDR
# Tested on: Debian and Ubuntu Linux
# Author: Vivek Gite {https://www.cyberciti.biz} under GPL v2.x+
# ——————————————————————
file=”/tmp/out.txt.$$”
wget -q -O “$file” https://openai.com/gptbot-ranges.txt 2>/dev/null
while IFS= read -r cidr
do
sudo ufw deny proto tcp from $cidr to any port 80
sudo ufw deny proto tcp from $cidr to any port 443
done < “$file”
[ -f “$file” ] && rm -f “$file”
Related
Also, check all our complete firewall tutorials for Alpine Linux Awall, CentOS 8, OpenSUSE, RHEL 8, Debian 12/11, Ubuntu Linux version 16.04 LTS/18.04 LTS/20.04 LTS, and 22.04 LTS.
Putting a Stop to Google AI (Bard and Vertex AI generative APIs)
You can counter this by adding the below mentioned two lines to your robots.txt:
User-agent: Google-Extended
Disallow: /
If you wish to see more information, here’s a catalog featuring the user agents implemented by Google crawlers and fetchers. It should be noted though that Google doesn’t provide CIDR, IP address ranges, or autonomous system information (ASN) to obstruct its AI bot that could be utilized with your web server firewall.
Preventing Access for Commoncrawl (CCBot)
Add the subsequent two lines in your robots.txt:
User-agent: CCBot
Disallow: /
Despite the fact that Common Crawl is a not-for-profit organization,
the data it generates is used by everyone to instruct their AI through its bot known as CCbot. Therefore, it’s crucial to prevent them as well.
But, akin to Google, they do not offer CIDR, IP addresses, or autonomous system numbers (ASN) to block its AI bot, which could be used with your website server firewall.
Can AI bots ignore my robots.txt file?
Well-established companies such as Google and OpenAI typically adhere to robots.txt protocols. Robots.txt File, but some poorly designed AI bots will ignore your robots.txt.
Is it possible to block AI bots using AWS or Cloudflare WAF technology?
Cloudflare recently announced that they have introduced a new firewall rule that can block AI bots. However, search engines and other bots can still use your website/blog via its WAF rules. It is crucial to remember that WAF products require a thorough understanding of how bots function and must be implemented carefully. Otherwise, it could result in the blocking of other users as well. Here is how to block AI bots using Cloudflare WAF:
Can I block access to my code and documents hosted on GitHub and other cloud-hosting sites?
No. I don’t know if that is possible.
I am concerned about using GitHub, a Microsoft product, and the largest investor in OpenAI. Robots.txt File, they may use your data to train AI through their ToS updates and other loopholes. It would be best if your company or you hosted the git server independently to prevent your data and code from being used for training. Big companies like Apple and others prohibit the internal use of ChatGPT and similar products because they fear it may lead to code and sensitive data leakage.
Is it ethical to block AI bots for training data when AI is being used for the betterment of humanity?
I have doubts about using OpenAI, Google Bard, Microsoft Bing, or any other AI for the benefit of humanity. It seems like a mere money-making scheme, while generative AI replaces white-collar jobs. However, if you have any information about how my data can be utilized to cure cancer (or similar stuff), please feel free to share it in the comments section.
Robots.txt File, my personal thought is that I don’t benefit from OpenAI/Google/Bing AI or any AI right now. I worked very hard for over 20+ years, and I need to protect my work from these big techs profiting directly. You don’t have to agree with me. You can give your code and other stuff to AI. Remember, this is optional. Robots.txt File, the only reason they are now providing robots.txt control is because multiple book authors and companies are suing them in court. Besides these issues, AI tools are used to create spam sites and eBooks. See the following selected readings:
- Sarah Silverman sues OpenAI and Meta
- AI image creator faces UK and US legal challenges
- Stack Overflow is ChatGPT Casualty: Traffic Down 14% in March
- Authors are spamming out Kindle Books using ChatGPT
- ChatGPT banned in Italy over privacy concerns
- AI Spam Is Already Flooding the Internet and It Has an Obvious Tell
- Artificial intelligence could lead to extinction, experts warn
- AI is being used to generate whole spam sites
- Company Plans to Ditch Human Workers in Favor of ChatGPT-Style AI
- Inside the secret list of websites that make AI like ChatGPT sound smart
Indeed, the current reality is that AI utilizes the bulk of our data. However, these methods can safeguard any content we generate in the future.
Conclusion
In the wake of generative AI’s increased popularity, content creators are starting to challenge the unauthorized use of their data by AI companies for model training purposes. Robots.txt File, these companies profit off the code, texts, pictures, and videos produced by millions of small and independent creators, thereby undermining their income sources. While some might not object, it’s known that this rapid shift negatively impacts many. Hence, the blocking of undesired AI crawlers should be a facile task for website operators and content creators. This means that the procedure should be uncomplicated.
This page will be regularly updated as additional bots become available for blocking through the use of robots.txt file and cloud solutions provided by third-party companies such as Cloudflare, among others.
Other open-source projects for bot blocking
- Nginx Bad Bot and User-Agent Blocker
- Fail2Ban sifts through log files like /var/log/auth.log and bars IP addresses that have numerous unsuccessful login attempts.
ColoCrossing excels in providing enterprise Colocation Services, Dedicated Servers, VPS, and a variety of Managed Solutions, operating from 8 data center locations nationwide. We cater to the diverse needs of businesses of any size, offering tailored solutions for your unique requirements. With our unwavering commitment to reliability, security, and performance, we ensure a seamless hosting experience.
For Inquiries or to receive a personalized quote, please reach out to us through our contact form here or email us at sales@colocrossing.com.

